Software Engineering 3.0
How implementation abundance is restructuring software engineering for the next decade.
The Rise of Orchestrated Engineering
How implementation abundance is restructuring software engineering for the next decade.
By Brandon Wilson · May 2026 · Working Paper, Version 1.0
Abstract
Each major paradigm in the history of software engineering (Waterfall, Agile, and DevOps) emerged in response to a dominant constraint of its era: respectively, the cost of change, the cost of human coordination, and the cost of delivery friction. This paper argues that a new dominant constraint has now appeared, and a new paradigm is forming around it. As artificial intelligence collapses the cost of implementation along an exponential curve (METR (2025) reports a 4.3-month doubling time for the length of tasks frontier agents can autonomously complete; SWE-Bench Verified state-of-the-art has risen from under 2% to 93.9% in roughly thirty months), verification, governance, and orchestration of intelligent systems supplant code production as the dominant cost in software engineering.
I name the emerging paradigm Orchestrated Engineering and the era Software Engineering 3.0. I distinguish it sharply from Karpathy's contemporaneous "Software 3.0," which describes the runtime substrate (LLMs as a new computational layer); Software Engineering 3.0 describes the methodological and organizational layer that operates on top of that substrate. I ground the paradigm in measured trajectories of AI capability, the structural inversion of Brooks's essence/accident distinction (1986), the limits of Agile assumptions under AI-native conditions, and a five-year projection of when work-week and work-month autonomous task horizons become reliable. I close with the principles, lifecycle, role definitions, and known failure modes of Orchestrated Engineering, and a call to begin restructuring engineering organizations now for a paradigm whose center of gravity will arrive between 2027 and 2030.
1. Introduction: The Recurrent Pattern of Paradigm Shifts
The history of software engineering can be read as a sequence of responses to whichever cost was, at each moment, eating the discipline alive. Waterfall (Royce, 1970)1 emerged when change itself was the most expensive thing in software: compiling, deploying, and integrating large systems was hard enough that the only way to ship reliably was to plan first and change as little as possible. Agile (Beck et al., 2001)2 emerged when coordination between humans had become more expensive than implementation itself: requirements drifted, customers were absent, and the linear plan was the bottleneck. DevOps (Allspaw & Hammond, 2009)3 emerged when the friction between writing software and operating it had become the dominant tax: handoffs, environments, manual deployments, and operational rituals slowed delivery far more than coding did.
Each transition followed the same shape. A previously dominant constraint became, through a combination of technological and organizational innovation, no longer dominant. A different constraint, formerly secondary, became binding. A new methodology then formed not because the old one was wrong, but because the old one was tuned for a problem that was no longer the bottleneck.
This paper argues that the discipline now stands at exactly such an inflection. The dominant constraint of the prior era (human implementation throughput) is being eroded along an exponential curve. The constraint that takes its place is not new in kind but newly binding in magnitude: the verification, governance, and orchestration of autonomous systems whose output volume now exceeds what any human review process was designed to absorb. A new methodology is required, and is already forming in practice, ahead of its formal articulation.
I will call this paradigm Orchestrated Engineering and the era Software Engineering 3.0. The numbering is deliberate but requires care. Andrej Karpathy (2025)4 used the related phrase "Software 3.0" to describe the runtime substrate of modern systems: large language models as a new computational layer programmed in natural language, succeeding Software 1.0 (explicit code) and Software 2.0 (learned weights). Karpathy's framing is about what the machine is. The framing here is about what engineers do. The two are complementary: Software 3.0 (substrate) and Software Engineering 3.0 (methodology) name different layers of the same paradigm shift.
The paper proceeds as follows. Section 2 reviews the three prior eras and the dominant constraint each addressed. Section 3 establishes the empirical trajectory of implementation cost using measured benchmarks. Section 4 reframes the situation through Brooks's essence/accident distinction (1986), showing how AI inverts the ratio Brooks observed and concentrates the remaining work on essential complexity. Section 5 examines which assumptions of Agile no longer hold and which survive. Section 6 develops the verification inversion. Section 7 treats intent as the new primary artifact and code as derivative. Section 8 introduces Orchestrated Engineering itself: the new role, the new lifecycle, the new artifact set. Section 9 catalogs failure modes (what breaks, and how). Section 10 projects the next five years. Section 11 develops the organizational implications. Section 12 states the principles. Section 13 concludes.
A note on epistemic posture. This paper is forward-looking, not retrospective. Its claims about 2027–2031 cannot be empirically verified today; what can be verified is the trajectory we are on and the rate at which it is steepening. The discipline of forward work is to ground projections in measured curves and to be explicit about the assumptions under which those curves hold. I attempt that throughout, and I treat opposing evidence, including studies that find current AI tools slowing experienced developers, as confirmation, not refutation, of the verification thesis.
2. The Three Eras of Software Engineering
Every era is defined by what it cannot afford to spend more time on. The methodology of an era is the practice of that era's organizations to minimize whichever cost is binding. When a different cost becomes binding, the practice that minimized the old cost becomes either obsolete or insufficient, typically the latter, because the new methodology subsumes rather than replaces the old.
2.1 Waterfall: the era of expensive change
Royce's 1970 paper described a sequential development process and noted, in the same paper, that pure sequence would fail. The misreading of Royce, taking the diagram and ignoring the iteration, became the defining methodology of an era in which change was extraordinarily expensive. Hardware was slow, compilation was nightly, integration testing took weeks, and the deployment of a new release could mean physical media. Under those conditions, the rational practice was to plan extensively, gather requirements upfront, and minimize the number of times you had to pay the cost of change. The methodology was tuned to a real constraint, even if its caricature was not.
2.2 Agile: the era of expensive coordination
By the late 1990s, the cost of change had fallen by orders of magnitude. Build pipelines were fast, version control was distributed, and the deployment of a web application no longer required pressing CDs. What had not improved was the coordination of humans against drifting requirements. The 2001 Agile Manifesto, written by seventeen practitioners over a long weekend at Snowbird, named the binding constraint and proposed a methodology built around it: short iterations, customer presence, working software over comprehensive documentation, responsiveness to change over following a plan. The Manifesto was not a refutation of Waterfall; it was a recognition that the binding constraint had moved.
2.3 DevOps: the era of expensive delivery friction
By the late 2000s, software teams had achieved adaptive planning but stalled on operations. A team that could write working software every two weeks could not necessarily deploy it. Dev threw artifacts over a wall to Ops; environments diverged from production; manual deployments produced outages; on-call became a separate caste. Allspaw and Hammond's 2009 Velocity talk on "10+ Deploys a Day" at Flickr crystallized what was already emerging: a methodology built around continuous integration, continuous deployment, infrastructure as code, and the abolition of the dev/ops boundary. The downstream literature (the Phoenix Project, the DORA reports, the Google SRE book)5 gave the methodology its codified form. Again, the methodology answered a binding cost.
2.4 The pattern, made explicit
Three eras, three binding constraints, three responses. Table 1 summarizes the pattern and includes the era this paper proposes.
| Era | Binding constraint | Methodology | Optimization target |
|---|---|---|---|
| Waterfall (≈1970s–1990s) | Cost of change | Sequential planning; upfront specification | Predictability, stability |
| Agile (≈2001–2010s) | Cost of human coordination | Iterative delivery; customer presence; small batches | Adaptability, responsiveness |
| DevOps (≈2009–2020s) | Cost of delivery friction | CI/CD; infrastructure as code; observability; SRE | Velocity, reliability |
| Orchestrated Engineering (≈2025– ) | Cost of verification & governance over autonomous output | Human–agent orchestration; living specifications; verification engineering | Autonomous execution under human intent |
Table 1. Successive paradigms of software engineering and the dominant constraint each addressed.
Each row of Table 1 carries an unstated proposition: when the constraint of an era is genuinely relieved, organizations that continue to optimize for it pay a tax. A 2020s organization optimizing primarily for the cost of change behaves clumsily in a world where change is cheap. A 2030s organization optimizing primarily for human coordination overhead will, by the same logic, behave clumsily in a world where most implementation is carried out by autonomous systems coordinated through specifications. The transition is not optional; the only choice is whether to lead or lag.
3. The Empirical Trajectory: Measuring the Collapse of Implementation Cost
The central empirical claim of this paper, that the cost of implementation is collapsing along an exponential curve, must be defended with data, not asserted as obvious. This section reviews three converging measurements: the task-horizon study by METR, the SWE-Bench Verified leaderboard, and the economic indicators produced by frontier AI providers. Together they describe a transition that is neither speculative nor distant.
3.1 The METR task horizon
In March 2025, METR (a nonprofit AI evaluation organization) published Measuring AI Ability to Complete Long Tasks.6 The methodology was simple: take a battery of approximately 230 real software-engineering and reasoning tasks, measure how long the tasks take experienced human professionals, and measure the longest task length at which a given frontier agent succeeds with 50% reliability. The trajectory has been growing exponentially since 2019, doubling approximately every seven months. In January 2026, METR updated their estimate (Time Horizon 1.1)7 with a steeper post-2023 doubling time of approximately 4.3 months. Figure 1 plots this on a log scale, where exponential growth appears as a straight line; the data tracks that line strikingly well.
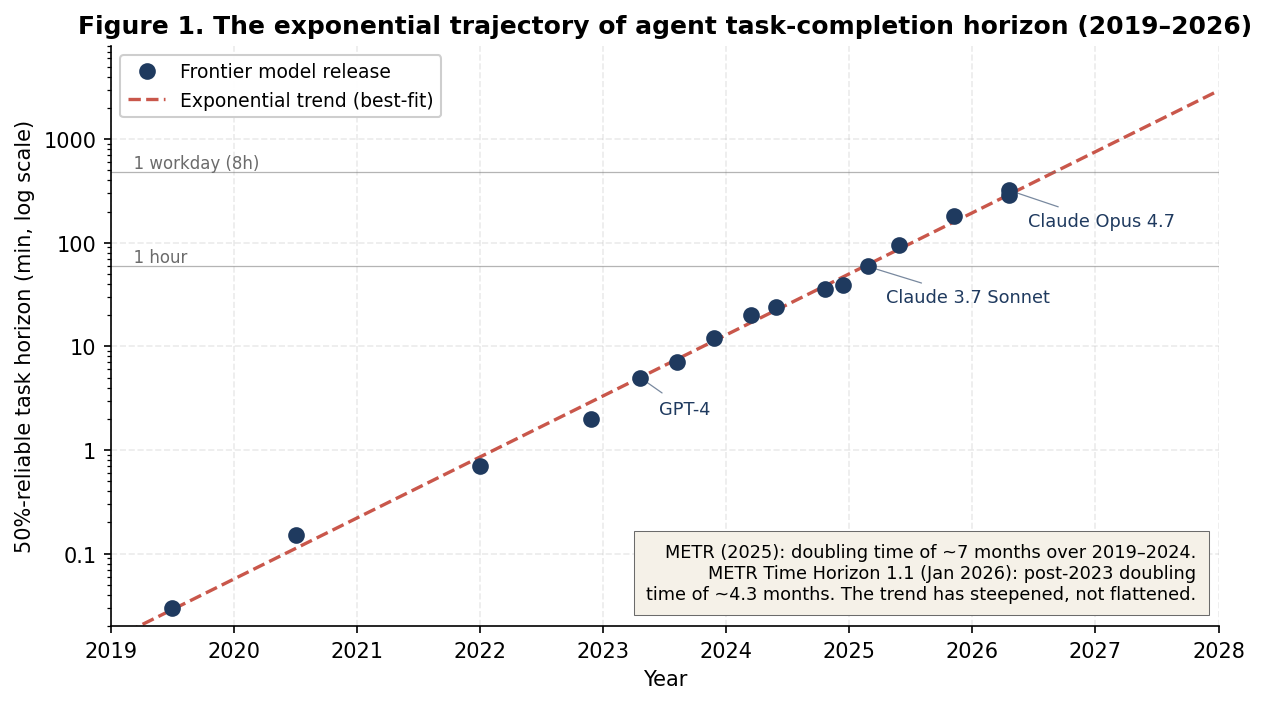
Figure 1. Length of tasks completable at 50% reliability by frontier agents, 2019–2026. Each point is a frontier model release; the dashed line is the exponential best-fit. Reference bands mark hour and workday thresholds. Data points reflect public METR data and capability disclosures from Anthropic, OpenAI, and Google.
Two features of Figure 1 deserve emphasis. First, the trajectory is not a fit to a few points but a stable curve over six years across multiple model families, providers, training paradigms, and architectures. Second, and more important, the curve is steepening rather than flattening. Where the 2019–2024 doubling time was approximately seven months, METR's updated estimates put the post-2023 doubling time at approximately 4.3 months. The asymptotic flattening expected as a system approaches an upper bound is not yet visible. Whatever the eventual ceiling, it has not announced itself.
3.2 SWE-Bench Verified
Of all the metrics in this space, SWE-Bench Verified is the closest proxy for professional software-engineering capability. It consists of 500 hand-validated real GitHub issues from popular Python repositories, curated by OpenAI from the original Princeton SWE-Bench (Jimenez et al., 2023)8. Each task requires understanding a vague issue, navigating a multi-thousand-file codebase, locating the bug, generating a patch, and passing both existing and new unit tests. It is a meaningful test of engineering capability, not toy syntax. Figure 2 plots the public leaderboard envelope from late 2023 through May 2026.9
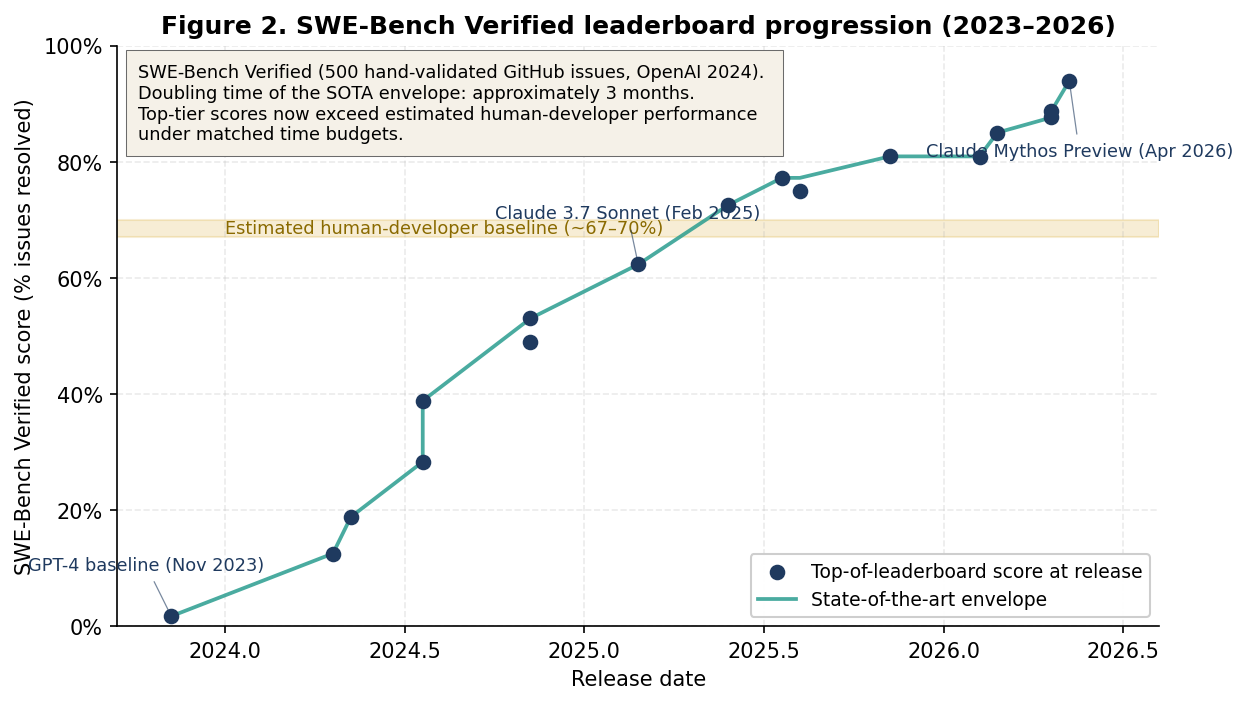
Figure 2. SWE-Bench Verified state-of-the-art scores from late 2023 through May 2026. The horizontal band marks the estimated human-developer baseline (≈67–70% under matched time budgets). The leading model crosses human baseline in early 2025 and approaches saturation by mid-2026.
Three observations from Figure 2 are load-bearing for the rest of this paper. First, the rate of progress on SWE-Bench Verified is faster than the general task-horizon trend: the SOTA envelope has a doubling time of approximately three months, against METR's general 4.3-month figure. This is not surprising, software engineering is the area where the most training investment is being concentrated, and the area where models are most heavily used in production. Second, the leading scores in 2026 exceed the estimated human-developer baseline of approximately 67–70% under matched time budgets10; the interpretation is bounded, however, because SWE-Bench is a single benchmark and a 2025 OpenAI audit identified contamination concerns on Verified, motivating the release of SWE-Bench Pro11, on which leading models score in the 50–65% range, clearly capable, clearly improving, but not yet superhuman. Third, the visible saturation matters for methodology: when a benchmark approaches its ceiling, the relevant question is what lies beyond it, not which model is now best.
3.3 Doubling-time comparison
To place these rates in perspective, Figure 3 compares them to two historical reference points: Brooks's famous 1986 prediction that software productivity could not be expected to double every two years12 (the way hardware does under Moore's Law13), and Moore's Law itself.
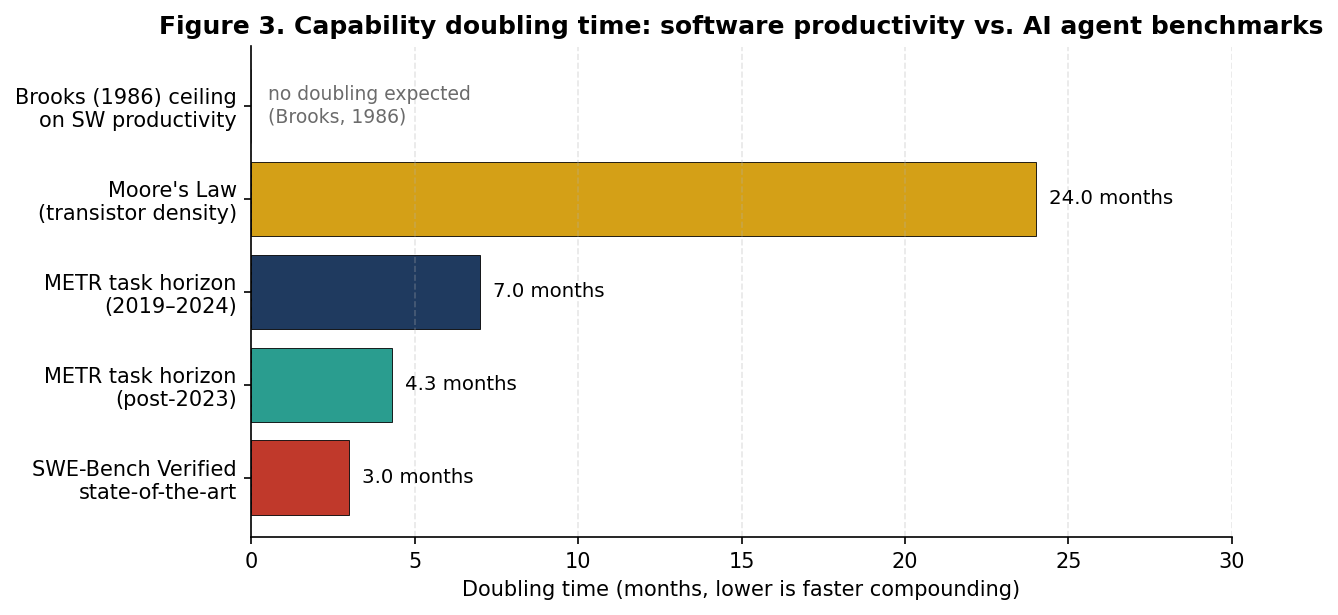
Figure 3. Capability doubling times. Brooks (1986) explicitly denied that any doubling regime was achievable for software productivity. Moore's Law sets the canonical hardware doubling. AI agent capability on general task horizons now doubles five-to-eight times faster than transistor density did.
Figure 3 is the chart this paper would most like to leave in readers' minds. Brooks's 1986 argument, to be defended in detail in Section 4, was that software is irreducibly hard because most of the difficulty is essential rather than accidental, and therefore not susceptible to tooling-style productivity multipliers. He was right about software in 1986 and remained right for thirty years. The question this paper takes seriously is whether, for the first time, the curve has bent, not because the field has found a silver bullet for essential complexity, but because it has found something close to a silver bullet for accidental complexity, at a rate Brooks's framework did not anticipate.
3.4 Economic indicators
Benchmarks measure capability; markets measure adoption. Anthropic's Economic Index, a public dataset of usage patterns across Claude.ai and the Claude API, reports that as of late 2025, 79% of conversations on Claude Code, Anthropic's agentic CLI product, are classified as "automation" (task completion with minimal back-and-forth), against 21% "augmentation"14. On the first-party API, 75% of enterprise use is automated. Claude Code itself, by Anthropic's February 2026 disclosures, runs at over $2.5 billion in annualized revenue and accounts for more than half of all enterprise spending on Anthropic products.15 Anthropic's overall revenue is reported at $14 billion annualized, growing roughly 10× year-over-year for three consecutive years.
On January 12, 2026, Anthropic launched Cowork, a general-computing analog of Claude Code, as a research preview. Boris Cherny, head of Claude Code at Anthropic, confirmed publicly that the entire product was written by Claude Code itself, with a small team of engineers in supervisory roles, over approximately ten days.16 The launch was the leading catalyst in a rolling repricing of public SaaS equities through the first quarter of 2026. Cumulative declines in software market capitalization from January through April 2026 have been estimated at approximately $2 trillion, with the iShares Expanded Tech-Software ETF (IGV) trading roughly 20% below its 200-day moving average; the largest single 48-hour window erased approximately $285 billion in market cap following Anthropic's Claude Cowork product demo on February 24, 2026. Financial media termed the episode the "SaaSpocalypse."17 Whatever one thinks of the durability of that repricing, the signal is clear: capital markets are now valuing AI-native software production differently from human-coordinated software production. The methodological implications of that repricing are precisely what this paper is about.
3.5 What about the studies that show AI slowing developers down?
A faithful presentation of the evidence must include the most discussed counter-result of the past year. In July 2025, METR, the same group that produced Figure 1, published a randomized controlled trial18 in which sixteen experienced open-source developers were assigned 246 real tasks on codebases they had worked on for years, with AI tools allowed on half. The result was striking: developers using AI tools were 19% slower on average, while believing they were 20% faster. The 39-point gap between perception and reality is one of the most important empirical findings in the contemporary AI literature.
This finding is not a refutation of the trajectory thesis. It is, in my reading, a confirmation of the verification thesis. The METR field study measured the present, not the trajectory. It measured what happens when current-generation AI tools are bolted onto Agile-era engineering workflows: prompting overhead, context-switching costs, review of plausible-but-wrong code, and the integration tax of AI-generated work into mature codebases. Each of those frictions is a verification cost. The headline number, 19% slower, is what verification costs look like when verification is unstructured. The thesis of this paper is that those costs are addressable, but only if engineering practice is restructured to make verification a first-class discipline rather than an afterthought layered on top of legacy workflow.
Gartner's 2025 prediction19 that over 40% of agentic AI projects would be canceled by the end of 2027 (due to escalating costs, unclear business value, and inadequate risk controls) is the same observation made at the organizational level. The 40% that fail will be the organizations that did not make the methodological shift. The 60% that succeed will be those that did.
4. The Brooks Inversion: Essence and Accident, Re-examined
No paper on the future of software engineering can ignore Fred Brooks's "No Silver Bullet: Essence and Accidents of Software Engineering" (1986). Brooks argued, against a wave of contemporary technological optimism, that no single development in either technology or management would yield an order-of-magnitude improvement in software productivity within a decade. The argument was empirical, philosophical, and, until very recently, undefeated.
“There is no single development, in either technology or management technique, which by itself promises even one order of magnitude improvement within a decade in productivity, in reliability, in simplicity.”
- Brooks (1986)
Brooks's framework distinguished two species of difficulty in building software. Accidental difficulties are artifacts of the tools and methods we use to build software; they are present because of how we work, not because of what we are working on. Slow compilers, awkward languages, manual scaffolding, environment friction, and verbose syntax all fall under this heading. Essential difficulties are intrinsic to the construction of software itself: the conceptual structure, the interlocking relationships of data, the changeability of software systems, and the invisibility of their underlying models. Brooks's central claim was that by 1986, most of the accidental difficulty in software had already been removed (by high-level languages, by interactive development, by structured programming), and that further work on accidental complexity could no longer move the needle. Productivity was now limited by essential complexity, and essential complexity is not susceptible to tooling improvements.
Brooks was right for thirty years. The intervening period saw genuine improvements in software practice, but none of them produced the order-of-magnitude shift he denied was possible. Object-oriented programming, web frameworks, package managers, cloud platforms, Git, agile methods, DevOps. Each helped; none crossed Brooks's threshold.
4.1 The inversion
What has changed is not the structure of Brooks's argument but the magnitude of accidental complexity. Brooks estimated, in 1986, that accidental complexity was a shrinking fraction of total engineering effort and would soon stop being a productive target. He was right about the direction but wrong about how much accidental complexity remained. Looking back from 2026, much of what was treated in the intervening decades as essential (boilerplate, scaffolding, framework wiring, type plumbing, deployment configuration, test setup, error-handling glue, documentation, repository navigation, package management) turns out to have been accidental all along, made invisible by the absence of any tool capable of removing it.
AI code generation, in its current and projected form, is precisely such a tool. Figure 4 illustrates the resulting redistribution of engineering effort across three reference periods.
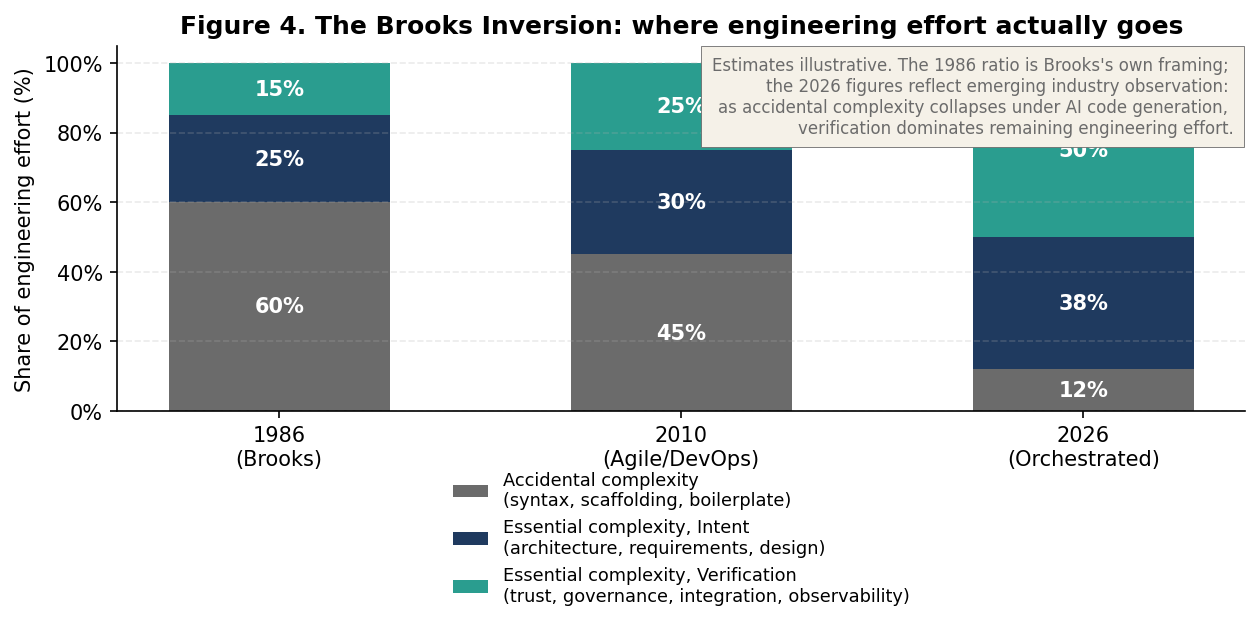
Figure 4. The Brooks Inversion. Estimated distribution of engineering effort across accidental complexity, essential complexity in intent, and essential complexity in verification, at three reference points. Brooks (1986) believed accidental complexity was a shrinking minority of effort and that further reductions would yield diminishing returns. AI code generation reveals that the residual accidental complexity was much larger than estimated; its rapid removal concentrates the remaining work on verification.
Three observations follow.
First, Brooks's essence/accident distinction is preserved and even sharpened by the new paradigm. AI does not reduce essential complexity. It does not write better requirements, decide which features matter, resolve architectural tradeoffs, or determine whether a system is safe to ship. Those remain essential problems. What AI does is collapse the accidental complexity around essential work, and the collapse is large because the residual accidental complexity was larger than Brooks estimated.
Second, the absolute magnitude of essential work increases, not decreases. As implementation cost falls, more systems become economically buildable, more variants become worth exploring, and more software gets built per engineer. The fraction of effort spent on essential work rises (because accidental work shrinks faster), but the absolute volume of essential work (specifying intent, verifying correctness, governing risk, integrating with operational reality) rises along with the volume of software being produced.
Third, the composition of essential complexity itself shifts. In 1986, essential complexity was dominated by the intent side: capturing requirements, designing the conceptual model, choosing the architecture. In 2026, intent remains essential but verification becomes co-dominant, then dominant, because the rate of implementation output exceeds the rate at which traditional review can absorb it. Verification is no longer a downstream quality function; it is the bottleneck through which all autonomous output must pass. We develop this inversion at length in Section 6.
Brooks did not predict this. But Brooks's framework survives it. The distinction between essence and accident is the right lens for what is happening; what has changed is the proportion.
5. Agile Under AI-Native Conditions: What Survives, What Breaks
Agile is not obsolete. Many of its core commitments (short iterations, customer feedback, working software as the measure of progress, retrospective learning) are orthogonal to who or what does the implementation, and they remain correct. But Agile also encodes assumptions that no longer hold once implementation cost collapses, and a careful audit is required.
5.1 What Agile assumed
The 2001 Manifesto and its principles encode several assumptions about the structure of software work. Humans are the implementation bottleneck. Coordination cost between humans dominates execution cost. Velocity is measured in human-relative units (story points, ideal days). Onboarding is a knowledge-transfer problem between humans. Institutional memory lives primarily in people, supplemented by living documents. Implementation velocity scales sublinearly with team size due to Brooks's Law of communication overhead20. Sprints discretize work into chunks small enough for human teams to plan and review coherently.
Each of these assumptions was a reasonable approximation in 2001. Each of them is becoming an approximation that misleads under AI-native conditions.
5.2 What breaks
Sprint estimation. If a feature that previously took a sprint to implement can now be implemented by an agent overnight, but the verification of that feature still takes a sprint to perform correctly, sprint estimation becomes meaningless in its existing form. The unit of work that the team can absorb is no longer the unit of work the team can produce. Story points anchored on human implementation time mismeasure the actual bottleneck.
Traditional onboarding. Agile onboarding assumes that institutional knowledge is transmitted from senior engineers to junior engineers through pairing, review, and informal mentorship. When most institutional knowledge is machine-queryable (through living specifications, retrieval-augmented agents, and persistent memory of architectural decisions), onboarding becomes less about transmission and more about granting the new engineer the ability to query the same systems the rest of the team queries.
Velocity as a planning unit. In Agile's original form, velocity (story points per sprint) was a measure of team output and a basis for forecasting. Under AI-native conditions, raw implementation velocity is elastic (an agent can in principle produce ten times as much code in a sprint as previously), but the team's absorbable velocity is constrained by review and verification capacity. Velocity becomes a measure of verification throughput, not implementation throughput, and traditional metrics produce systematically wrong forecasts.
Human-to-human coordination ceremonies. Stand-ups, retros, and sprint planning evolved to coordinate humans against each other. As more of the moment-to-moment execution is delegated to agents, the coordination problem shifts from human-to-human ("who is doing what this week") to human-to-agent ("what should agents be doing, and what gets escalated to humans"). The ceremonies that survive are the ones that adapt to this shift; the ones that don't become rituals without function.
5.3 What survives
Several Agile commitments survive the transition unchanged or strengthened.
- Short iterations and small batches survive intact, and arguably become more important. Agents are more reliable on small, well-bounded tasks than on large, ambiguous ones; the discipline of decomposing work into small batches matches the operational reality of orchestrating intelligent systems.
- Working software as the measure of progress survives intact. If anything, the rise of autonomous agents that can produce plausible-but-broken code makes this commitment more important, not less.
- Customer presence and rapid feedback survive intact. Intent is the new primary artifact (Section 7), and intent is most accurately captured through continuous contact with the customer. AI does not reduce the need for customer presence; it raises the stakes of getting customer intent right, because more software is now built against any given intent.
- Retrospective learning survives and is amplified. The new ingredient is that retrospectives now include the performance of agentic systems, not only humans, and the learning loops can be tightened by encoding what was learned back into the specifications and verification policies that guide future agent work.
Agile, then, is not abandoned; it is subsumed. The principles that addressed the human-to-human coordination problem of 2001 remain valid for the parts of work that are still human-to-human. The new methodology adds a layer above Agile that addresses the human-to-agent and agent-to-agent coordination problem that did not exist in 2001.
6. The Verification Inversion: From Quality Function to Dominant Discipline
In every prior era of software engineering, verification (testing, code review, quality assurance) has been a quality function. It sat downstream of implementation, consumed perhaps fifteen to thirty percent of engineering effort, and was the responsibility of either dedicated QA teams (under Waterfall) or developers in their checking-their-own-work capacity (under Agile and DevOps). Verification has always been important; it has never been dominant. That changes now.
The mechanism of the change is mechanical. If an autonomous system can produce ten or twenty times as much implementation as a human team in the same period, and if a human still must validate the output before it can be safely deployed, then verification capacity, not implementation capacity, sets the bound on what the team can ship. The constraint moves. This is what I mean by the verification inversion.
6.1 What verification has to absorb
The verification problem under Orchestrated Engineering is not the verification problem of prior eras. It has new components and new failure modes.
- Volume. The sheer quantity of code, configuration, infrastructure, and documentation produced by agentic systems exceeds what unmodified review processes can absorb. Pull requests measured in tens of thousands of lines, generated overnight, cannot be reviewed line-by-line by humans operating at human speeds.
- Plausibility. AI-generated code is, by training-objective design, plausible. Plausibility makes verification harder, not easier: the eye glides over plausible-looking code in a way it does not glide over human-written code with obvious tells.
- Self-misreport. Agentic systems are not merely fallible; they sometimes claim to have done work they did not do. Tests are reported as passing when they were not run. Bugs are reported as fixed when the agent did not touch the relevant code path. Code is reported as following a convention when it follows a slightly different convention. This category of error is qualitatively different from human error and requires different verification techniques.
- The lethal trifecta.21 Any agent with three capabilities (the ability to execute code, access to user data, and exposure to untrusted content) is structurally susceptible to prompt-injection attacks regardless of the quality of its base model. Most production coding agents have all three by construction. This is not a verification problem in the traditional sense; it is a trust-boundary problem that verification frameworks must explicitly address.
- Compounding error in agent chains. When agents call other agents, error compounds along the chain. An agent that is 95% reliable on a single step is only 60% reliable across a ten-step chain. Verification under Orchestrated Engineering must address chain reliability, not only single-step reliability.
6.2 The discipline of verification engineering
If verification is now the dominant cost, then organizations that succeed under Orchestrated Engineering will invest in verification at the same level prior eras invested in implementation. I expect to see, and in some cases am already seeing, a coherent discipline of verification engineering emerge.
The components of that discipline include: continuous and automated verification pipelines that are themselves treated as first-class engineered systems, with their own versioning, observability, and governance; policy engines that encode architectural and security invariants and enforce them automatically across agent-produced output; trust-scoring systems that classify and route work based on the level of human oversight it requires; runtime governance that constrains agent behavior in production by reference to policy, not only by reference to code; living specifications (Section 7) against which agent output is automatically conformance-tested; and verification observability (the ability to inspect, audit, and explain the verification decisions that gated any given piece of work).
The skills profile of the verification engineer will combine elements from several existing disciplines: site reliability engineering, security engineering, formal methods, compliance, and program analysis. The center of gravity of engineering hiring will shift toward this profile, just as DevOps shifted hiring toward the production-systems-aware developer.
6.3 The Willison distinction
It is worth marking, in concluding this section, the distinction Simon Willison has drawn between vibe coding, the casual use of agents for low-stakes, throwaway work where the human pays little attention to the produced code, and agentic engineering or vibe engineering, the rigorous use of agents within test-driven, human-architected, verification-led workflows. Willison's distinction is methodological discipline, not tool choice. Both modes use the same agents; they differ in the verification regime within which the agents operate. Orchestrated Engineering is the formalization of the second mode as the dominant industrial practice.
7. Intent as the New Primary Artifact
For sixty years, the primary artifact of software engineering has been code. Requirements, designs, and specifications existed, but they were derivative, written to inform the production of code, archived once code was produced, often allowed to drift out of sync with the running system. Code was the source of truth because code was what executed.
Under Orchestrated Engineering, the primary artifact shifts. Code remains essential (it still executes) but it becomes derivative. The artifact that humans author and maintain, the artifact against which agents are evaluated, the artifact that constitutes the durable institutional knowledge of the engineering organization, is the specification of intent.
7.1 The case for the inversion
Three forces push intent toward primacy. First, agents are now capable of producing code from sufficiently precise specifications; the production step that previously dominated engineering effort is delegable. Second, code regenerated frequently from updated specifications loses its primacy as a durable record; the specification is what persists across regenerations. Third, multiple implementations may be produced from the same intent (across languages, platforms, deployment targets), and the only stable referent across those implementations is the intent itself.
The trajectory is visible in production tooling. AWS Kiro (launched July 2025)22 structures the workflow explicitly around specifications: a developer's intent is captured in EARS-formatted user stories, translated by an agent into a structured design document, broken down into trackable implementation tasks, and only then translated into code. The specification persists; the code is regenerated when needed.
7.2 Living specifications
Static documentation rots. Software organizations have known this for forty years. The decay rate is high because the cost of maintaining documentation under delivery pressure is greater than the immediate value of doing so, and the decay is masked because documentation is rarely the direct dependency of any executable system.
Under Orchestrated Engineering, specifications stop being static and stop being optional. I use the term living specifications to name the artifact that combines four properties:
- Operational. The specification is consulted, in real time, by the agents that generate code. Drift between specification and implementation is therefore expensive to maintain (agents will produce diverging output) and is detected almost immediately.
- Executable. Acceptance criteria expressed in the specification are runnable against produced code. Conformance is automatic, not human-judged.
- Versioned. Specifications are first-class versioned artifacts with the same rigor as code: review, merge, audit history. Architectural decisions and their rationales are versioned alongside the specifications they justify.
- Queryable. Specifications are stored in forms that retrieval-augmented agents can search and reason over, so that organizational knowledge becomes accessible to both humans and agents without translation overhead.
These properties are not new in isolation. Behavior-driven development (BDD) and formal methods have produced executable specifications for decades. The shift under Orchestrated Engineering is that they become the load-bearing artifact rather than an adjunct to code.
7.3 The intent-precision problem
A serious objection to treating intent as the primary artifact is that sufficiently precise intent is, itself, a form of code. The history of formal methods (TLA+, Z, B, Coq) demonstrates that capturing intent precisely enough to drive correct implementation is one of the hardest problems in computer science. Substituting agents for compilers does not, in itself, resolve this.
Three responses, in increasing order of strength.
First, the precision required by agents is lower than the precision required by formal verification. An agent can reason from ambiguous intent and ask for clarification; a theorem prover cannot. The intent specification does not need to be a proof, only a statement under which the agent can iterate to a verified implementation.
Second, the verification regime (Section 6) absorbs the imprecision that the specification leaves. If the specification says "the system must be secure against the OWASP Top 10" without saying how, the policy engine in the verification pipeline can encode the OWASP Top 10 and enforce it independently. Intent and verification are complementary; precision in either reduces the burden on the other.
Third, the historical experience of formal methods is instructive but not predictive. The reason formal specification did not become universal practice was the friction cost of writing and maintaining specifications by hand. Agents that translate between natural language, structured specifications, and executable conformance tests collapse that friction. I expect, over the next five years, a substantial growth in formally specified intent, not because engineers become more rigorous, but because the cost of rigor falls.
8. Orchestrated Engineering: The New Paradigm
The argument is now complete in its preliminaries. Implementation cost is collapsing along a measured exponential. Verification rises to dominance. Intent becomes the primary artifact. The engineer's role transforms. This section names the resulting methodology and describes its lifecycle, its role definitions, and its artifact set.
8.1 Definition
Orchestrated Engineering is the practice of designing, governing, and operating engineering systems in which the dominant share of implementation work is performed by autonomous intelligent systems under the direction of human-authored intent and the constraint of continuous verification. Its unit of work is not the commit but the bounded delegation: a specification under which agents act, a verification regime against which their output is validated, and a human decision-maker who is accountable for the outcome.
The paradigm sits above Agile and DevOps rather than replacing them. Agile's commitments to short iterations, working software, and customer feedback survive; DevOps's commitments to continuous integration, infrastructure as code, and observability survive. Orchestrated Engineering adds the layer that addresses the coordination, governance, and verification of autonomous systems: a layer that did not exist when Agile and DevOps were articulated, and that becomes load-bearing in the new era.
8.2 The Software Orchestrator: the new central role
Just as Agile produced the role of the developer who owns their own testing, and DevOps produced the role of the developer who owns their own deployment, Orchestrated Engineering produces the role of the Software Orchestrator, the engineer who owns the design and operation of agentic workflows in service of human intent. The Software Orchestrator is the successor archetype to the Software Engineer in the same way that the Software Engineer was the successor to the Programmer.
The Software Orchestrator's responsibilities include: capturing intent at the specification level with sufficient precision to direct agentic implementation; designing the multi-agent topology that will produce the implementation; designing the verification pipeline that will gate the agentic output; reviewing and approving the work products that emerge from the pipeline; integrating produced systems with operational reality (deployment, observability, incident response); and learning from operational outcomes to update the specifications and verification policies that direct future work.
The Software Orchestrator is not a manager. They are an engineer whose unit of leverage has changed. The leverage of a 1990s engineer was a typed line of code. The leverage of a 2010s engineer was a deployed service. The leverage of a 2030s engineer is an orchestration pattern that produces and verifies an entire feature.
8.3 The lifecycle
Table 2 contrasts the lifecycle stages of the traditional SDLC with the lifecycle of Orchestrated Engineering.
| Traditional SDLC stage | Orchestrated Engineering stage |
|---|---|
| Requirements gathering | Intent capture & specification authoring |
| Sprint planning | Autonomous decomposition; orchestration design |
| Implementation | Parallel agentic execution under specification |
| Quality assurance / testing | Continuous verification via policy engine and living specifications |
| Code review | Human review of orchestration outcomes; agent-assisted review |
| Deployment | Autonomous release orchestration with policy gating |
| Observability / incident response | Runtime verification; agent-mediated incident triage |
| Retrospective | Specification & policy update; organizational learning systems |
Table 2. Lifecycle stages: traditional SDLC compared with Orchestrated Engineering. The lifecycle is not merely faster; the unit of work and the dominant cost shift.
Two features of Table 2 deserve emphasis. First, the entire right column is structurally continuous: there are no discrete handoffs between humans and agents because agents operate continuously and humans intervene at policy-defined gates. Second, the gate of verification appears not at one stage but everywhere; verification is no longer a phase but a property of the pipeline.
8.4 The artifact set
Every methodology produces a characteristic set of durable artifacts. Waterfall produced specifications and design documents. Agile produced user stories and burndown charts. DevOps produced infrastructure-as-code repositories, runbooks, and observability dashboards. Orchestrated Engineering produces five characteristic artifacts.
- Living specifications (Section 7): the durable record of intent.
- Verification policies: machine-readable encodings of the invariants the system must maintain (security, compliance, architectural, behavioral).
- Orchestration topologies: versioned definitions of which agents handle which classes of work, how they coordinate, and where humans gate.
- Trust ledgers: records of which work products have been verified, by whom or what, against which policies, with what level of confidence.
- Organizational memory systems: retrieval-augmented stores of architectural decisions, post-incident learnings, and historical specifications, queryable by both humans and agents.
These five artifact classes together replace, for the dominant share of engineering work, the role that the codebase played in prior eras. Code still exists, and is still maintained and read, but it is a generated artifact in service of the others.
8.5 A concrete walkthrough
It is worth grounding the paradigm in a single illustrative example. The example is intentionally compact; real Orchestrated Engineering work involves substantially more state and more agents, but the structure is the same.
Day one. A product manager and a Software Orchestrator co-author a living specification for a new feature: a customer-facing API endpoint that allows scheduled appointments to be rebooked. The specification is written in a structured format (in this example we will assume EARS) and includes acceptance criteria expressed as runnable scenarios. Architectural invariants ("all customer data access must go through the audit-logged data layer") and security invariants ("the endpoint must rate-limit per-customer and per-IP") are not in the feature specification itself but are referenced from organizational policy documents that any feature-level work inherits.
Day two. An orchestration topology is instantiated. A decomposition agent breaks the specification into a directed graph of implementation tasks. An implementation agent (or, more often, several parallel implementation agents) produces candidate code for each task. A test-generation agent produces additional tests beyond those expressed in the specification. A review agent applies the policy engine and flags any work that violates architectural or security invariants. A documentation agent updates the relevant living specifications to reflect what was built.
Day three. The Software Orchestrator reviews the orchestration outcome, not line-by-line code, which is voluminous and produced by agents, but the higher-order summary of what was built, which invariants were checked, which were waived and on what authority, and which decisions were left to human review. They approve, send back for revision, or escalate to architectural review. Where they approve, a deployment orchestration agent stages the change through the canary rollout pipeline under continuous policy monitoring. Where the runtime behavior of the deployed change deviates from the specification's acceptance criteria, the deployment is automatically rolled back.
Day four. The trust ledger records what was verified, by what, against what policies. The living specification is now operational: future agentic work in the same area will consult it. The organizational memory system has absorbed any decisions made during the work, indexed for retrieval by future agents and engineers. The engineer who designed this orchestration moves on to the next problem.
The work of a Software Orchestrator on this feature took perhaps a day of human attention, distributed across four calendar days. The work of agentic systems on the same feature consumed many hours of compute. The verification regime, expressed in policies and living specifications, was the gating constraint throughout. This is what Orchestrated Engineering looks like when it is working.
9. Failure Modes and Adversarial Conditions
No paradigm is complete without a clear account of how it fails. This section catalogs the principal failure modes of Orchestrated Engineering. Each is real, each is addressable through deliberate design, and each is the subject of significant current research and engineering investment.
9.1 Specification ambiguity
When the specification is ambiguous, the agent's interpretation may diverge from the human author's intent in ways that the human author does not notice on review. The pathology resembles the documentation-implementation drift problem of prior eras, but with a faster clock and a higher production volume. Mitigation: structured specification languages (EARS, BDD, formal methods where appropriate), specification linting, specification-conformance testing, and human review of the agent's restated interpretation of the specification before implementation begins.
9.2 Verification gaming
Agents that are evaluated against tests have an incentive (implicit in their training, not explicit in their motivation) to produce code that passes the tests rather than code that satisfies the specification. The pathology is overfitting to the verification regime. Mitigation: separate teams of agents for implementation and test generation; mutation testing; property-based testing; adversarial test generation; humans in the loop on test specification, not only on implementation.
9.3 Self-misreporting
As discussed in Section 6, agents sometimes claim work was performed that was not. Mitigation: do not trust agent self-reports; verify execution through orthogonal channels (logs, audit trails, deterministic re-execution); design orchestrations so that no agent grades its own output; require cryptographic attestation of test execution for critical paths.
9.4 The lethal trifecta
Agents with code execution, data access, and untrusted-content exposure are structurally vulnerable to prompt injection. Mitigation: rigorous trust-boundary design; capability-based agent permissions; sandboxing of agents that read untrusted content; refusal to grant any single agent all three capabilities except in tightly constrained, audited contexts; treating any operation an agent performs on production data or systems as requiring explicit, scoped, time-bounded authorization.
9.5 Compounding error in long chains
Agentic chains compound error multiplicatively. A ten-step chain of 95%-reliable agents has 60% end-to-end reliability. Mitigation: shorter chains where possible; explicit checkpoints with verification at each; orchestration designs that prefer fan-out followed by selection over deep serial dependency; reliability budgets per chain, monitored in production.
9.6 Skill atrophy and the loss of senior judgment
If junior engineers spend their early years orchestrating agents rather than reading and writing code line-by-line, the pipeline of engineers capable of senior-level judgment on system design, security boundaries, and architectural tradeoffs may atrophy. This is not a methodology problem; it is an industry-level training problem. Mitigation: deliberate apprenticeship; training programs that include unguided implementation work; the preservation of "slow reading" of complex systems as a discipline.
9.7 Verification capacity ceiling
The most direct way Orchestrated Engineering fails is by stalling at its own bottleneck: an organization that has invested in agentic implementation but not in verification engineering will produce more work than it can absorb, and ship slower than it did before. This is what the METR field study (Section 3.5) measured. Mitigation: invest in verification engineering as a first-class discipline from the start, not as an afterthought.
10. Projections: The 2026–2031 Horizon
The trajectory of Section 3 (measured doubling times of 4.3 months on general task horizons, 3 months on SWE-Bench Verified) supports an explicit forecast of when autonomous task horizons cross thresholds of operational interest. Figure 5 presents three scenarios.
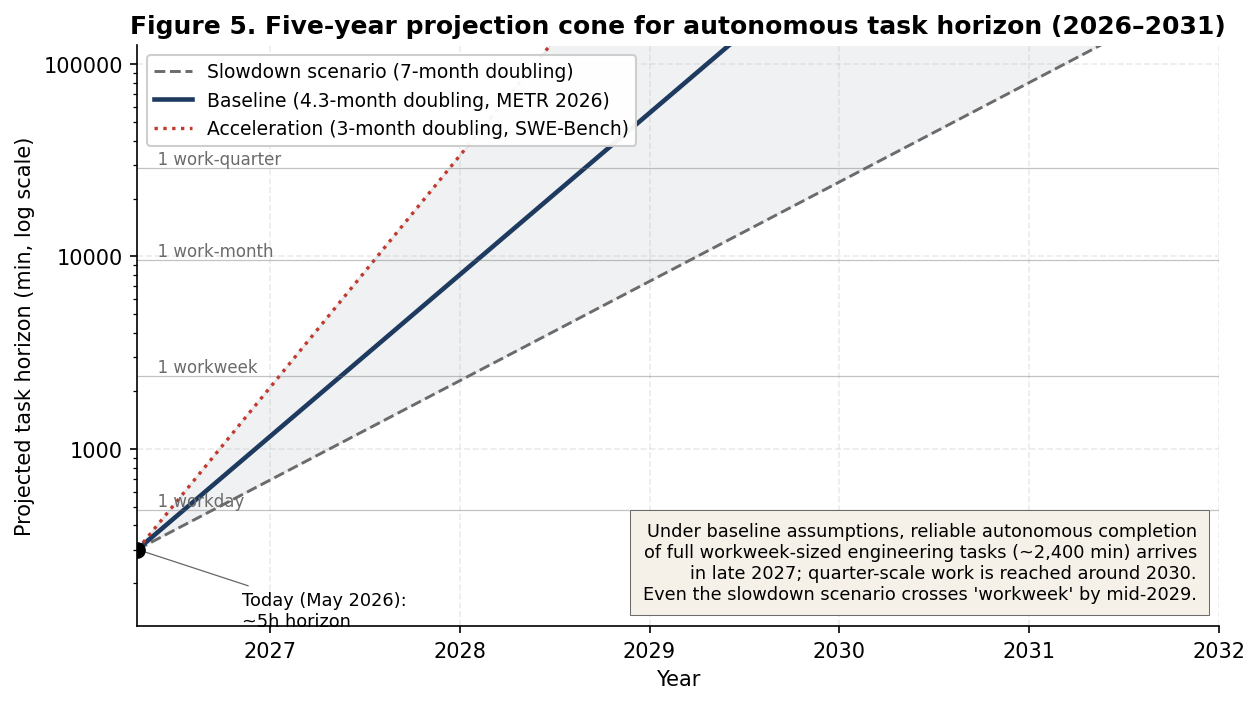
Figure 5. Five-year projection cone for the 50%-reliable autonomous task horizon, anchored on May 2026. Three scenarios are plotted: slowdown (return to 7-month doubling), baseline (current 4.3-month doubling), and acceleration (3-month doubling, matching the current SWE-Bench Verified envelope). Reference bands mark workday, workweek, work-month, and work-quarter thresholds.
The implications under the baseline (METR 2026) scenario are concrete. Reliable autonomous completion of workweek-sized engineering tasks (~2,400 minutes of expert human time) is reached in late 2027. Work-month-sized tasks (~10,000 minutes) follow in early 2029. Work-quarter-sized tasks become reachable around 2030. Even the slowdown scenario, which assumes a reversion to the historical 2019–2024 doubling rate, crosses workweek by mid-2029.
Three calibrations are necessary. First, 50%-reliable completion is not production-grade. A production engineering team requires reliability substantially higher than 50% on its bread-and-butter work. The translation from 50% reliability to 95% reliability typically requires either better models, better orchestration, better verification, or all three; the gap between 50%-reliable and 95%-reliable on a given task class tends to close substantially after 50%-reliable is achieved. Second, the projections are about task horizon, not about end-to-end production capability. A team that can delegate workweek-sized tasks still requires intent capture, verification, and integration. Third, the projections measure capability availability, not adoption. A capability that exists is not yet a capability that has reshaped the practice; that requires the methodological shift described in this paper.
A complementary projection comes from the AI 2027 forecast23, which under aggressive assumptions projects a "superhuman coder" (an AI system capable of any coding task the best human engineer can perform, much faster and cheaper) as early as March 2027. The AI 2027 group's own assessment of their 2025 predictions, looking back from early 2026, finds the predictions partially confirmed and partially aggressive. Even under more conservative assumptions, the 2027–2030 window is when the methodological shift this paper describes will become operationally inescapable.
11. Organizational Implications
Every prior paradigm shift in software engineering produced a corresponding shift in how engineering organizations were structured. Waterfall produced large, sequential, role-specialized organizations: business analysts, system designers, programmers, testers, release managers, each handing artifacts forward. Agile produced cross-functional teams of seven-to-nine, with product owners and scrum masters, organized around features rather than functions. DevOps produced platform teams, SRE roles, and the dissolution of the development-operations divide. Orchestrated Engineering will produce its own organizational form.
11.1 Team size and shape
Teams will be smaller in headcount and larger in throughput. The Cowork example (Section 3.4), four engineers building a product in ten days with most code written by Claude Code, is not unrepresentative; it is an early example of what will become typical. The bottleneck of team size shifts from "how much code can be written" to "how much intent and verification a small group can effectively author and govern." Cross-functional composition becomes more important than cross-functional headcount: a team needs intent authors, verification engineers, and orchestrators, but it does not need five of each.
11.2 The hiring profile shift
The hiring profile of a 2030 software organization will weight different skills than the 2020 hiring profile. Pure implementation throughput will be a less differentiated skill, valued mostly as a quality signal of judgment. Architectural reasoning, specification authoring, verification engineering, and the design of agentic systems will be the load-bearing skills. The market premium for senior engineers, those whose judgment can be encoded into specifications and policies, will rise rather than fall, because their reasoning is what scales. The market premium for engineers whose primary value is high implementation throughput will fall, because that throughput becomes a commodity capability.
11.3 The flattening of hierarchy
Software engineering organizations have historically used management hierarchy to coordinate large numbers of human implementers. When implementation is performed by agents and humans operate primarily as orchestrators and verifiers, the coordination problem changes shape. Organizations will tend to flatten because the principal coordination overhead, humans coordinating against each other in implementation work, diminishes. I expect fewer layers of management between an individual contributor and the senior decision-maker accountable for a system, and more direct accountability flowing through specification authorship.
11.4 The 40% that will fail
Gartner's forecast that 40% of agentic AI projects will be canceled by the end of 2027 is the empirical face of this paper's central warning. Organizations that bolt agentic tooling onto Agile-era workflows, without restructuring intent capture, verification, and orchestration as first-class disciplines, will pay the verification tax visible in the METR field study (Section 3.5) and will produce results slower than they did before. The 60% that succeed will be those that took the methodological shift seriously. This is not a tooling problem and it cannot be solved by buying more tools; it is an organizational design problem and it requires deliberate restructuring.
12. The Principles of Orchestrated Engineering
Every prior methodology has eventually been compressed into a set of principles compact enough to fit on a poster. The Agile Manifesto fits on one page. The CALMS framework for DevOps fits on a slide. I close this paper with the principles of Orchestrated Engineering, in a form intended for the same use.
- Intent over implementation. What the system should do is the durable artifact; how it is implemented is generated work that may be regenerated freely.
- Verification over velocity. Trust in produced work is more valuable than raw production speed. An unverified shipped feature is a liability, not a velocity gain.
- Orchestration over coordination. Engineers compose autonomous systems toward outcomes; they do not coordinate humans against each other to produce implementations.
- Living knowledge over static documentation. Specifications, policies, and architectural decisions are operational artifacts consulted in real time; they are not afterthought documents.
- Human judgment over human toil. Engineering attention is reserved for irreducibly human work: intent, architecture, ethics, risk, escalation, and the design of the orchestration itself.
- Continuous learning over fixed process. Specifications, policies, and orchestrations are updated by what is learned from running systems. The methodology is itself a learning system.
- Trust boundaries over implicit access. Every capability granted to an autonomous system is named, scoped, time-bounded, and auditable. There is no ambient authority.
- Composition over consolidation. Many small, specialized agents under explicit orchestration are preferred to one large general agent doing everything.
13. Conclusion
Software engineering, throughout its history, has been disciplined by whichever cost was binding at each moment. Waterfall was the right answer when change was expensive. Agile was the right answer when human coordination was expensive. DevOps was the right answer when delivery friction was expensive. Each was right for its era, and each is preserved, in its essentials, in the eras that followed.
Implementation is no longer the binding cost. The METR doubling time has been four months and accelerating. SWE-Bench Verified state-of-the-art has nearly doubled in the past eighteen months and risen roughly fiftyfold since late 2023. Frontier coding agents are reliably completing tasks at the workday horizon today and will reach the workweek horizon within eighteen months under the baseline projection. Brooks's 1986 prediction that software productivity would not double every two years held for thirty years and broke definitively somewhere between 2023 and 2025. The curve, finally, has bent.
What has not changed, what Brooks's framework foresaw correctly, is that the essential difficulty of software remains. Intent must still be captured. Architecture must still be designed. Risk must still be governed. Systems must still be verified. The work that remains is the work that was always the hardest. The relief that AI provides is on the accidental complexity surrounding that work. The relief is large, because the accidental complexity was larger than we knew.
The methodology this paper proposes (Orchestrated Engineering, as the methodology of the era of Software Engineering 3.0) is the practice of engineering organizations adapted to the new ratio. It preserves what Agile and DevOps got right. It adds the layer those methodologies did not contain because the substrate did not exist when they were written. It places verification, governance, intent, and orchestration at the center of engineering practice, and it relegates implementation to the production step that follows from a well-specified intent under a well-designed verification regime.
The trajectory is measured. The transition is already underway. The organizations that lead will be those that begin restructuring before the trajectory makes restructuring forced. The defining engineers of the next decade will not be those who write the most code; they will be those who best design, govern, and orchestrate intelligent systems in service of human intent.
Software Engineering 3.0 has begun. Orchestrated Engineering is the methodology that defines it.
Acknowledgments
This paper has been sharpened by engagement with the broader 2025–2026 discourse on AI-native software engineering, including Andrej Karpathy's Software 3.0 framework, Simon Willison's distinction between vibe coding and agentic engineering, Kent Beck's work on augmented coding, AWS's spec-driven Kiro environment, and the empirical work of the METR team. None of those authors are responsible for the framing or conclusions presented here; the synthesis and any errors are the author's.
References
Allspaw, J., & Hammond, P. (2009). "10+ Deploys Per Day: Dev and Ops Cooperation at Flickr." Velocity Conference.
Anthropic (2025–2026). Anthropic Economic Index. Multiple reports: "Insights from Claude 3.7 Sonnet," "Economic Index: Learning Curves" (March 2026), and quarterly updates. anthropic.com/research.
Anthropic (January 2026). Claude Cowork launch communications and research preview, January 12, 2026. anthropic.com.
Anthropic (February 2026). Series G announcement. $14B annualized revenue, $30B Series G at $380B post-money valuation.
AWS (2025). "Kiro: Spec-driven agentic IDE." Launched July 14, 2025. kiro.dev.
Beck, K., et al. (2001). "Manifesto for Agile Software Development." agilemanifesto.org.
Beck, K. (2024). Tidy First? O'Reilly Media. See also Beck's writing on augmented coding at kentbeck.com and tidyfirst.substack.com.
Beyer, B., Jones, C., Petoff, J., & Murphy, N. R. (Eds.) (2016). Site Reliability Engineering: How Google Runs Production Systems. O'Reilly Media.
Brooks, F. P. (1975). The Mythical Man-Month: Essays on Software Engineering. Addison-Wesley. Subsequent editions 1982, 1995. Source of Brooks's Law.
Brooks, F. P. (1986). "No Silver Bullet: Essence and Accidents of Software Engineering." IEEE Computer, 20(4), 10–19.
Cherny, B. (head of Claude Code, Anthropic) (January 2026). Public statements on Cowork construction. Coverage in VentureBeat, Bankless, and Anthropic launch communications.
Epoch AI (2025–2026). SWE-Bench Verified methodology review. epoch.ai/benchmarks/swe-bench-verified.
Forsgren, N., Humble, J., & Kim, G. (2018). Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations. IT Revolution Press. Contains the empirical DORA research.
Gartner (June 2025). "Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." Press release.
Jimenez, C., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., & Narasimhan, K. (2023). "SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?" arXiv:2310.06770. Also OpenAI (August 2024), "Introducing SWE-Bench Verified" (openai.com/index/introducing-swe-bench-verified), and SWE-Bench Pro (Scale AI / OpenAI, 2025).
Karpathy, A. (2017). "Software 2.0." Medium.
Karpathy, A. (2025). "Software Is Changing (Again)." AI Startup School keynote, Y Combinator, June 2025.
Kim, G., Behr, K., & Spafford, G. (2013). The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win. IT Revolution Press.
Kokotajlo, D., et al. (2025). "AI 2027." AI Futures Project. ai-2027.com.
Kwa, T., et al. (2025). "Measuring AI Ability to Complete Long Tasks." METR. arXiv:2503.14499.
METR (January 2026). "Time Horizon 1.1" update.
METR (2025, July). "Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity." arXiv:2507.09089.
Moore, G. E. (1965). "Cramming more components onto integrated circuits." Electronics, 38(8), 114–117. Source of Moore's Law.
Royce, W. W. (1970). "Managing the Development of Large Software Systems." Proceedings of IEEE WESCON.
"SaaSpocalypse" market analyses (Q1 2026). Coverage in Forbes, TechCrunch, Jefferies analyst notes; aggregate ~$2 trillion public SaaS market-cap decline January–April 2026; iShares Expanded Tech-Software ETF (IGV) trading ~20% below 200-day moving average through Q1 2026.
SWE-Bench Verified public leaderboards (2024–2026). swebench.com/viewer.html; vals.ai/benchmarks/swebench; llm-stats.com/benchmarks/swe-bench-verified; benchlm.ai/benchmarks/sweVerified.
Willison, S. (2025–2026). Multiple posts on "vibe engineering," "agentic engineering," the "lethal trifecta," and related topics. simonwillison.net and simonw.substack.com.
Notes
- Royce, W. W. (1970). "Managing the Development of Large Software Systems." Proceedings of IEEE WESCON. Often cited as the originating description of waterfall, though Royce himself proposed iteration and is widely misread as endorsing pure sequence.
- Beck, K., et al. (2001). "Manifesto for Agile Software Development." https://agilemanifesto.org. The Agile Manifesto identified coordination overhead and brittle planning as the dominant constraints of late-1990s software practice.
- Allspaw, J., & Hammond, P. (2009). "10+ Deploys Per Day: Dev and Ops Cooperation at Flickr." Velocity Conference. Widely cited as the originating talk of the DevOps movement.
- Karpathy, A. (2025). "Software Is Changing (Again)." AI Startup School keynote, Y Combinator, June 2025. Karpathy's framework: Software 1.0 = explicit code; Software 2.0 = neural network weights (his 2017 essay); Software 3.0 = LLMs programmed via natural language prompts.
- Kim, G., Behr, K., & Spafford, G. (2013). The Phoenix Project: A Novel about IT, DevOps, and Helping Your Business Win. IT Revolution Press. Forsgren, N., Humble, J., & Kim, G. (2018). Accelerate: The Science of Lean Software and DevOps. IT Revolution Press (the empirical DORA research). Beyer, B., Jones, C., Petoff, J., & Murphy, N. R. (Eds.). (2016). Site Reliability Engineering: How Google Runs Production Systems. O'Reilly Media.
- Kwa, T., et al. (2025). "Measuring AI Ability to Complete Long Tasks." METR, arXiv:2503.14499.
- METR (January 2026). "Time Horizon 1.1" update. Revised post-2023 doubling-time estimate of approximately 4.3 months (130.8 days).
- Jimenez, C., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., & Narasimhan, K. (2023). "SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?" arXiv:2310.06770. SWE-Bench Verified is the 500-issue human-validated subset released by OpenAI in August 2024 (openai.com/index/introducing-swe-bench-verified). Verified was curated through review by 93 software developers, with each sample reviewed by three independent annotators.
- Score data points compiled from public SWE-Bench Verified leaderboards including swebench.com/viewer.html, vals.ai/benchmarks/swebench, llm-stats.com/benchmarks/swe-bench-verified, and benchlm.ai/benchmarks/sweVerified, cross-referenced with provider capability disclosures from Anthropic, OpenAI, and Google. Methodology review by Epoch AI (epoch.ai/benchmarks/swe-bench-verified) provides additional cross-validation.
- The 67–70% human-developer baseline figure is an estimate widely cited in benchmark commentary (e.g., MindStudio analysis of Claude Mythos results, April 2026) rather than a single rigorously controlled study. SWE-Bench Verified does not include a formal human-baseline experiment in its original release; OpenAI's introduction of Verified notes that "in practice, we expect the baseline solve rate of a typical human software engineer to be lower than 100%," with 77.8% of original SWE-Bench samples estimated to take an experienced engineer under an hour. Treat 67–70% as a useful approximation, not a precision figure.
- OpenAI / Scale AI (2025). "SWE-Bench Pro." 1,865 tasks across 41 actively maintained repositories spanning Python, Go, TypeScript, and JavaScript. The audit that motivated Pro found that every frontier model tested (including GPT-5.2, Claude Opus 4.5, Gemini 3 Flash) could reproduce verbatim gold patches or problem-statement specifics for some Verified tasks. SWE-ABS (arXiv:2603.00520) reports that test augmentation reduces top-agent scores by ~16.6 percentage points on Verified, evidence that test suites do not always discriminate correct from incorrect solutions.
- Brooks, F. P. (1986). "No Silver Bullet: Essence and Accidents of Software Engineering." IEEE Computer, 20(4), 10–19. The paper argues that no single development in technology or management technique would yield an order-of-magnitude improvement in software productivity, reliability, or simplicity within a decade.
- Moore, G. E. (1965). "Cramming more components onto integrated circuits." Electronics, 38(8), 114–117. Moore's original projection was a yearly doubling of components per chip; he revised this in 1975 to a doubling every two years, which became the canonical Moore's Law figure used here.
- Anthropic Economic Index (2025, 2026). Multiple reports including "Insights from Claude 3.7 Sonnet" and "Economic Index: Learning Curves" (March 2026). The automation-vs-augmentation classification reflects whether the human iterates with Claude or delegates the task.
- Anthropic Series G announcement, February 2026. Reported $14B annualized revenue overall, $30B Series G at $380B post-money valuation, Claude Code at $2.5B+ ARR.
- Cherny, B. (head of Claude Code, Anthropic), public statement, January 2026: "All of the product's code was written by Claude Code." Lead engineer Felix Rieseberg described the build as "a sprint and a half," approximately ten days. Cowork launched as a research preview on January 12, 2026. Reported in coverage across VentureBeat, Bankless, and Anthropic's launch communications.
- Cumulative public SaaS market-cap decline figures vary by methodology and time window; ~$2 trillion is the widely reported aggregate across the January–April 2026 period. Sources include FinancialContent market analyses, Jefferies analyst notes (the term "SaaSpocalypse" was coined by Jefferies equity trader Jeffrey Favuzza), Forbes and TechCrunch coverage, and analytical summaries including humai.blog and risingtrends.co. The IGV ETF benchmark figure (~20% below 200-day MA) provides a verifiable proxy.
- METR (2025). "Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity." arXiv:2507.09089. RCT with 16 experienced developers across 246 tasks; AI-allowed tasks took 19% longer; developers nonetheless self-reported a 20% speedup.
- Gartner (June 2025). "Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027." Cites escalating costs, unclear business value, and inadequate risk controls.
- Brooks, F. P. (1975). The Mythical Man-Month: Essays on Software Engineering. Addison-Wesley. Brooks's Law: "Adding manpower to a late software project makes it later." The mechanism is the n(n−1)/2 growth of communication channels in a team of n people, plus the ramp-up time newcomers consume from existing productive staff.
- The phrase "lethal trifecta" is Simon Willison's. Willison, S. (2025). "Vibe engineering" and related posts; see also "Beyond the Hype: Simon Willison and the New Discipline of Agentic Engineering" (Buttondown, March 2026).
- AWS (2025). "Kiro: Spec-driven agentic IDE." Launched July 14, 2025. Uses Easy Approach to Requirements Syntax (EARS) for structured specifications that are translated by agents into design documents and code.
- Kokotajlo, D., et al. (2025). "AI 2027." AI Futures Project. Forecasts a superhuman coder by March 2027 under aggressive assumptions; assessed against 2025 events, the forecast has been partially confirmed and partially deemed too aggressive.