The model is free. Running it isn't.
Here's the thing nobody tells you when they say "AI is getting cheaper": there isn't one price curve. There are two, and they're moving in opposite directions.

I had a conversation with a co-worker this week that got me thinking. He'd been following Mark Cuban's argument that companies will eventually stop renting AI from the big providers and start running their own, and he raised it with me because it lines up with a lot of what I've been writing about. It's a sharp thread to pull on, and pulling on it sent me to read Cuban's actual words and then down into the pricing data, where I found something that reframes the whole question.
Here's the thing nobody tells you when they say "AI is getting cheaper": there isn't one price curve. There are two, and they're moving in opposite directions.
The first curve is the price of the frontier. What does it cost to access the single best model available on any given day? That number is sticky. GPT-4 launched in early 2023 at roughly $60 per million output tokens. OpenAI's leading reasoning model in late 2024 cost the same $60 per million. Frontier flagships in 2026 sit somewhere in the $20 to $75 range depending on the provider and the thinking mode. The frontier has gotten enormously more capable, but the price of standing at the frontier has barely moved. You're always paying roughly the same premium to be on the bleeding edge, because the bleeding edge is, by definition, the expensive part.
The second curve is the price of a fixed capability. What does it cost to get GPT-4-level performance, specifically, regardless of what the frontier is doing? That number is in freefall. a16z documented inference cost dropping a thousandfold in three years and called it "LLMflation." Epoch AI's more careful analysis found the rate ranges from 9x to 900x per year depending on which capability milestone you pin. Stanford's AI Index put GPT-3.5-level inference at a 280-fold decline between late 2022 and late 2024. The specific number depends on how you measure, but the shape is unmistakable: pick a capability, hold it fixed, and the price falls hard toward the cost of the raw compute underneath it. Not to zero, there's a floor set by the GPUs and the electricity, but toward it.
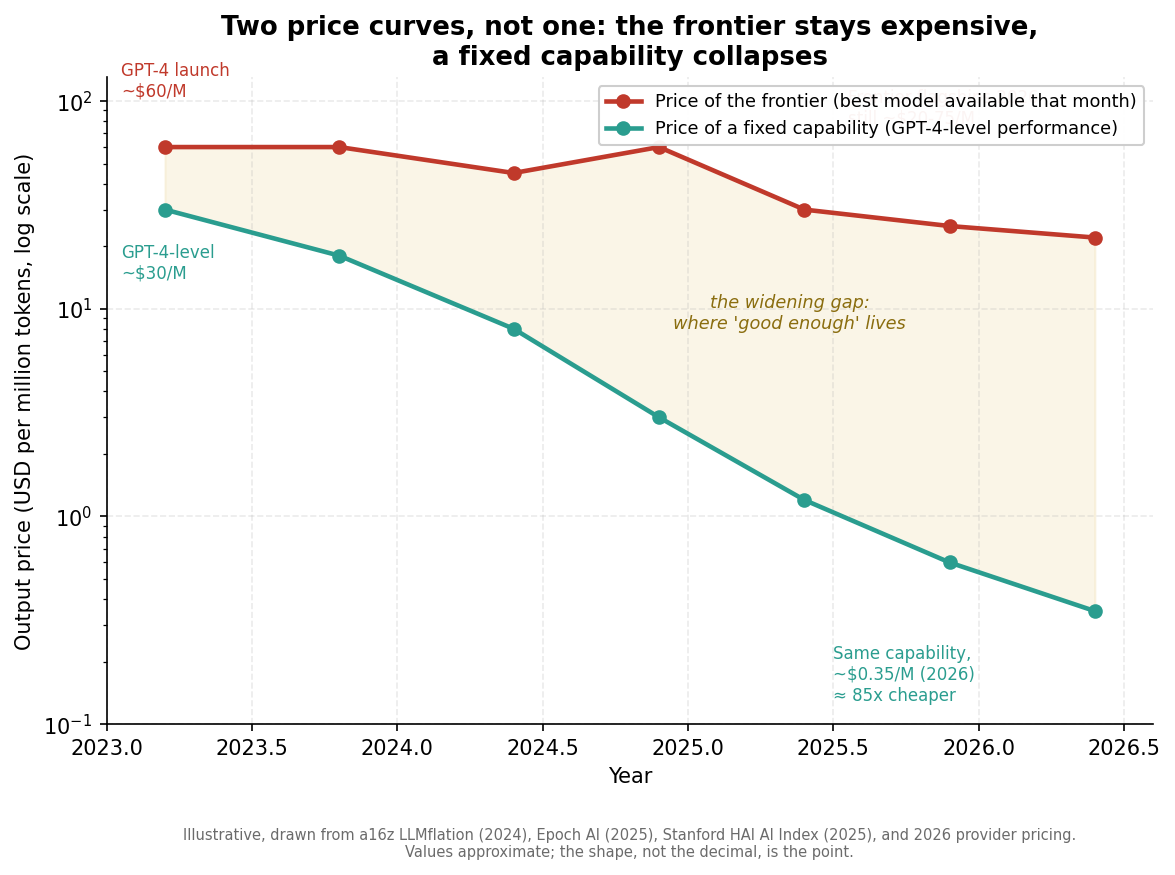

The gap between those two curves is the most important space in the AI economy right now, and it's where the whole question my coworker raised starts to come into focus.
The old model gets good enough, and then you just harvest the price drop
Walk through what actually happens over a year. Opus 4.7 ships today. It does some task X at price Y. A year from now Opus 5.0 ships, does more than X at the same price Y, and Opus 4.7 falls to a fraction of its launch price. Now: if task X was already solved well enough by 4.7, what changed for you? Nothing about your need. The frontier ran ahead, your problem stayed exactly where it was, and the only thing that moved is that solving it got cheaper. You ride the old model down the price curve and pocket the difference.
This is the part people get backwards when they talk about diminishing returns. The returns aren't diminishing on the model. The model keeps getting better every year. The returns are diminishing on your need. Once a model clears the difficulty threshold of the task in front of you, every subsequent capability gain is irrelevant to that task. Classification, extraction, summarization, routing, structured output, first-draft generation: most of these hit "good enough" a generation or two ago. For that work, the frontier is a spectator sport. What matters is the falling price of the capability you already have.
So the first answer to "has inference become cheap" is: for any task whose difficulty is stable, yes, dramatically, and it will keep getting cheaper whether or not you ever touch a newer model.
There's a second reason to bring it in-house, and it has nothing to do with cost
Cost is one driver. Cuban's actual argument points at a second one that operates completely independently.
His recent position, from early 2026, isn't really about model-building. It's about data. His point is that the second you hand your proprietary information to a third-party tool, you've potentially handed it to a competitor's future training set, and that in an AI economy, your data is the asset, It's more valuable than the patents you'd file or the papers you'd publish. He's gone as far as telling founders that "publish or perish" is now a mistake because publishing trains someone else's model. Whether or not you buy the strong version of that, the underlying observation is sound: there are categories of data you structurally cannot send to an external API, at any price, no matter how cheap it gets.
I work in healthcare. This isn't abstract for me. There is patient data that does not leave the building, full stop, and no per-token price will ever change that calculus. The decision to run inference in-house, for that data, was never going to be made on cost. It's made on control. And the control driver triggers at any volume. You don't need millions of tokens a month to justify it. You need one byte of something that can't go over the wire.
So now there are two independent triggers for bringing inference in-house. Cost triggers above a volume threshold. Control triggers whenever the data is too sensitive to externalize. Either one alone is enough.
What changed in 2026: both triggers got easy to satisfy at once
Here's the convergence that makes this a 2026 story and not a 2023 one. The "good enough" ceiling doesn't only apply to old closed models like last year's Opus. It applies to open-weight models too. And open weights have quietly become both good enough and cheap enough to operate.
Epoch finds open-weight models now lag the closed frontier by an average of about three months, sometimes closing the gap entirely. By this spring, DeepSeek's V4 Pro was matching the top closed models on most agentic benchmarks at roughly a tenth to a thirteenth of the cost per token, with closed models holding a real but narrowing lead on production coding, human preference, and the hardest reasoning tasks. Five independent open families (DeepSeek, Qwen, Kimi, GLM, Mistral) reached frontier-adjacent quality at roughly the same time, which makes the trend structural rather than a fluke of any one lab.
When a model you can download and run on your own hardware clears your task's difficulty threshold, you've satisfied both triggers in a single move. The high-volume commodity work gets cheaper because you're not paying API margins. The sensitive data stays inside your walls because the weights are sitting on your GPUs. Cost and control, solved together, by the same decision.
But you're not building a model. You're operating one.
This is where the popular shorthand around Cuban's argument needs a small but important correction, because the loose phrasing matters. Almost no company is going to train its own foundation model. That costs hundreds of millions of dollars and requires talent that a few dozen organizations on Earth are competing for. That door is closed and getting more closed.
What companies will increasingly do is operate and fine-tune open weights. Those are completely different activities with completely different cost structures, and conflating them is how people end up with bad expectations. You don't build DeepSeek. You download it, you fine-tune it on your proprietary data (which, conveniently, is exactly where the secrets argument pays off, because the fine-tuned model becomes the embodiment of your data advantage without that data ever leaving), and you run inference on infrastructure you control.
But "infrastructure you control" is itself a spectrum, and it's worth being precise about it, because "run your own model" gets used to mean four very different things. At one end is a managed open-weights service: Bedrock, Vertex, Azure AI, or specialists like Together and Fireworks, where you pick the open model but the cloud still operates the serving. You chose the weights; you don't touch the metal. One rung down, you run your own inference stack (vLLM, TensorRT-LLM, SGLang) on rented GPUs, an EC2 instance or a neocloud like CoreWeave, where the hardware is still someone else's but the model and the data path never leave your boundary. Further down still, you own the GPUs outright, in a colo or on-prem, for the cases where data sovereignty is absolute or your sustained volume makes owning cheaper than renting. And of course the starting point most people never leave is just calling a managed API. The interesting movement over the next five years isn't a wholesale return to the server room. It's the default sliding down a rung or two: from "rent the frontier model" toward "operate open weights on rented compute," with fully-owned hardware reserved for the genuinely sovereign cases. The metal mostly stays in the cloud. What changes is who picked the model, who controls the data path, and who runs the serving layer.
A note on the data-center boom, since it gets invoked here a lot: the hundreds of billions going into new capacity is mostly the providers and clouds building inference to rent to you, not companies building private fleets. More supply means cheaper rented GPUs, which if anything reduces the reason for a typical company to own hardware. The pull toward owning metal doesn't come from the buildout. It comes from three specific overrides: regulatory sovereignty, economics at extreme sustained utilization, and latency or air-gap requirements. For everyone else, the cloud's elasticity keeps winning.
And running it is the whole job. There's a line from a CTO-decision guide I read this week that I haven't been able to stop thinking about: picking a model is a one-week decision; operating a self-hosted inference stack (multi-node serving, quantization, eval pipelines, on-call) is a year-long engineering investment. The economics back this up. Self-hosting open weights tends to beat the API somewhere north of five to ten million tokens a month. Below that, the API is cheaper and you should just use it. Above it, and especially when control is in play, you're running your own.
Notice what that decision actually is. It's not a machine learning problem. It's an operations problem. Serving, scaling, reliability, cost-per-unit, observability, on-call. That's site reliability engineering. The model has been commoditized down to a one-week procurement decision, and the thing left standing, the thing that's hard and getting harder, is operating inference reliably and economically at scale.
The one thing that doesn't get cheaper
There's a tension I want to be honest about, because it's what keeps this from being a tidy story. "Good enough" is a moving target, and it moves up.
As work shifts from single model calls to long, autonomous, agentic chains (which I've argued elsewhere is exactly where engineering is heading), the difficulty threshold rises. A model that was good enough for a one-shot task might not be good enough when you're chaining it across thirty steps and errors compound at each one. So the frontier never fully dies. We keep inventing harder tasks that need it. The honest version of the this post is: for stable tasks, you ride the price curve down and you may well bring them in-house; for the expanding frontier of genuinely hard, long-horizon, novel work, you keep renting the best model that exists, because being a few months behind actually costs you something there.
Which means the future isn't "everyone builds their own." It's a tiered stack that didn't exist two years ago. Frontier API for the hard five percent where the top of the capability curve still moves the needle. Cheap, last-generation API for the work that was solved a generation ago and just needs to get cheaper. Open weights on infrastructure you control for the high-volume commodity work, and for any data can't leave the building. With routing logic deciding, request by request, which tier each piece of work belongs to.
Here's where it ties back to everything else I've been writing about. Across all three tiers, the hard part is identical and it has nothing to do with the model. You still have to specify intent precisely enough for the system to act on it. You still have to verify that what came back is correct. You still have to orchestrate the whole thing into a reliable workflow. Whether the tokens came from Opus 5.0, from a cut-rate Opus 4.7, or from a fine-tuned DeepSeek humming on a rack in your own data center, the verification and orchestration layer is the same, and it's the layer that isn't commoditizing.
The model is becoming a commodity, priced near the cost of running it rather than as a premium product priced on its intelligence. Running it, governing it, and trusting its output is the job. That was the job before the prices started falling, and it'll be the job long after they bottom out.